WinSetupFromUSB — инструкция пользования
Все знают, что существует возможность переустановки операционной системы или же ее замена другим дистрибутивом. Но многие...
Бесплатная программа для автоматического распознавания отсканированного текста. Вид у программы не карамельный, но дело своё она знает.
Компьютер уже уверенно вошел в жизнь рядового гражданина. Когда надо получить сравнительно небольшой объем печатной информации, проще всего набрать этот текст вручную при помощи текстового редактора.
Однако иногда надо «переписать» целую книгу. В таких случаях рациональнее всего использовать сканер. Но сам по себе сканер делает только фотокопию текста, которую никак нельзя редактировать. Для того, чтобы изменить информацию на полученном изображении следует провести распознавание документа.
Бесспорным лидером в этом деле является система OCR (англ. optical character recognition — оптическое распознавание текста) от Abbyy — FineReader. Но стоит она довольно дорого и не каждый может позволить себе иметь в своем арсенале такой инструмент. Сегодня мы познакомимся с бесплатной альтернативой Файн Ридера — программой CuneiForm . Приведу сравнительную таблицу возможностей обеих пакетов:
Как видим, если хочется бесплатно распознавать текст, придется кое в чем уступить. Первое, с чем придется смириться — неумение CuneiForm работать с некоторыми сканерами (в особенности сканерами МФУ). Поэтому придется сканировать документ при помощи стандартных функций Windows. Второе — надо следить за разрешением сканирования.
Это связано с тем, что CuneiForm не может обрабатывать большие файлы (свыше 100 Кбайт), а чем выше разрешение, тем больший размер файла-скана. Зато качество распознавания текста в программе намного выше, чем у платного конкурента, а поэтому оптимальным вариантом параметров скана будет 200 dpi (можно и больше, но тогда есть вероятность, что программа просто зависнет).
Количество языков тоже невелико, но основные есть. Более того, хоть комбинировать языки и нельзя, зато в CuneiForm есть смешанный англо-русский режим распознавания! На этом минусы заканчиваются:). Можно начинать установку.
Здесь сложностей нет, поскольку Вам поможет инсталлятор. Просто запускайте установочный файл и следуйте инструкциям. После установки в меню «Пуск» появится новый раздел. Открываем его и запускаем CuneiForm.

Интерфейс CuneiForm намного проще, чем у Fine Reader, и почти не требует настройки. Программой можно полностью управлять благодаря кнопкам на панели инструментов. Рассмотрим их более детально:

Программа может работать в режиме мастера, который активируется первой кнопкой. Но если CuneiForm не поддерживает Ваш сканер, то от этого режима стоит отказаться. Следующая кнопка запускает процесс сканирования (опять же, если есть поддержка сканера). На этой и следующих кнопках Вы можете заметить небольшие стрелочки. Нажав на них, мы получим доступ к некоторым дополнительным функциям.
Теперь давайте опробуем CuneiForm на практике. Если программа поддерживает Ваш сканер, то первой кнопкой, которую следует нажать, будет «Получить изображение». Если же такой возможности нет, то откроем уже готовый скан (поддерживаются форматы JPG, GIF, BMP, PNG (не всегда корректно), а также TIF (в полной мере)).

Теперь следует произвести разметку. Она помогает определить блоки, из которых состоит страница. Поддерживается распознавание блоков в виде текста (синяя рамка), рисунков (зеленая рамка) или таблиц (оранжевая рамка) (автоматическую разметку можно доработать вручную, используя контекстное меню блока).

Когда текст обозначен, самое время провести его распознавание. Для этого нажимаем следующую кнопку. По окончании процесса распознавания в рабочем окне отобразится текст, который можно редактировать в небольшом встроенном текстовом редакторе похожем на Microsoft Word. При этом Вы сразу сможете увидеть те слова, в которых программа «не уверена» (голубая подсветка) и в которых есть ошибка (сомнительная буква — розовая).

И, наконец, после успешного редактирования можно сохранить результат нашей работы. Кликаем последнюю кнопку на панели инструментов и сохраняем текст как RTF, HTML или TXT-файл.

Если же Вы желаете большего, то, нажав на стрелочку сбоку, Вы сможете выбрать опции экспорта в одну из предложенных программ (Microsoft Word, Excel или Евфрат).

Посмотрите на предыдущий скриншот. Наверняка вы обратили внимание, что в дополнительных меню кнопок, начиная с «Разметки» и заканчивая «Сохранением», есть в конце пункт «Автомат». Активирование этой опции освобождает Вас от нажатия выбранной кнопки. То есть можно автоматизировать процесс обработки скана до того, что Вы будете лишь открывать новый документ. Все остальное CuneiForm сделает сама!
Программа изначально настроена самым оптимальным образом, но если Вы что-то захотите изменить, просто зайдите в меню «Файл» и выберите опцию «Общие параметры». Это может пригодиться для смены языка и некоторых других параметров распознавания, форматирования и сканирования текстов.

На этом можно было бы и закончить, если бы в пакет CuneiForm не входила еще одна утилитка. Откройте «Пуск» снова и в папке с программой обнаружите еще одно приложение — «Пакетное распознавание». Представьте, что Вы отсканировали целую книгу! и теперь надо ее распознать!!! Если открывать каждый файл-скан по отдельности на это уйдет уйма времени, пакетный же режим представляет возможность указать нужные файлы, а об остальном программа позаботится сама.

Для начала нужно создать новый пакет файлов. Нажимаем соответствующую кнопку и следуем подсказкам запустившегося мастера:


По окончании распознавания Вы сможете увидеть в основном окне все распознанные документы. Если распознавание прошло успешно, то в левой боковой панели Вы обнаружите активными только два списка: «Исходные» и «Обработанные». Если же будут файлы, которые не удалось распознать, их мы найдем в разделе «Ошибки».

Потенциал у CuneiForm явно хороший, однако разработка ведется довольно медленно. Несмотря на открытый исходный код, компания Cognitive, видимо, очень требовательна к разработчикам, раз прогресс так долго не появляется. Остается только надеяться, что дело сдвинется с мертвой точки и программа станет еще лучше, а пока довольствуемся малым. Но такое ли уж оно и малое… Выбор за Вами!
подпишитесь на новые видеоуроки!
Основные возможности приложения
Все итоговые результаты, полученные в программе, можно сохранять практически во всех популярных форматах, а затем удобно и быстро находить их, используя полнотекстовый поиск.
CuneiForm отличается от других аналогичных программ высоким уровнем техники распознавания, мощнейшим текстовым редактором, наличием встроенных мастеров. Приложение распознает даже те сфотографированные или отсканированные тексты, которые отличаются особенно низким качеством.
Программа качественно преобразовывает электронные графические файлы и бумажные документы в текст для редактирования на уровне коммерческих утилит, являясь при этом абсолютно бесплатной.
Приложения с подобным функционалом: ABBYY FineReader , Tesseract, VietOCR и др.
В установке программы нет никаких сложностей, нужно только запустить специальный установочный файл и действовать согласно отображаемым инструкциям.
Интерфейс достаточно простой и практически не нуждается ни в каких дополнительных настройках. Основные операции выполняются с помощью кнопок, расположенных на панели инструментов.
Интерфейс CuneiForm
Для начала нужно убедиться, поддерживает ли программа ваш сканер. Если да, то можно нажимать на кнопку «Получить изображение» или открывать готовый скан. Далее производится разметка, распознавание и сохраняется результат в необходимом формате.
В настройках («Файл» - «Общие параметры») можно изменить язык и некоторые другие параметры форматирования, сохранения и сканирования.

Мастер распознавания: Изобажение

Общие параметры

Общие параметры
CuneiForm – довольно мощная и функциональная программа, при помощи возможностей которой можно распознавать любые сфотографированные и отсканированные тексты.
Дата добавления обзора: 05.07.2009 г.
Информация об OCR CuneiForm:
OCR CuneiForm может распознавать любые полиграфические, машинописные гарнитуры всех начертаний и шрифты, получаемые с принтеров за исключением декоративных и рукописных. В систему встроены специальные алгоритмы для распознавания текста с матричного принтера, плохих ксерокопий факсов и машинописи.
OCR CuneiForm это:
Основные возможности OCR CuneiForm
1. ИНТЕРФЕЙС
Интерфейс программы содержит выпадающие контекстные меню, панели быстрого доступа, контекстную помощь.
2. СКАНИРОВАНИЕ
3. ФРАГМЕНТАЦИЯ
4. РАСПОЗНАВАНИЕ
5. ЯЗЫКОВАЯ ПОДДЕРЖКА
Система распознает русский, английский, смешанный русско-английский, украинский, немецкий, французский, испанский, португальский, итальянский, голландский, датский, шведский, финский, сербский, хорватский, польский, казахский, узбекский и другие языки.
6. СЛОВАРНЫЙ КОНТРОЛЬ
7. РЕАЛИЗАЦИЯ ПРИНЦИПА "What You Scan Is What You Get" ("Что Вы сканируете, то и получаете").
CuneiForm позволяет получить полную копию вводимого документа, включая:
8. РАБОТА С ТАБЛИЦАМИ
9. РЕДАКТИРОВАНИЕ
В программу встроен многофункциональный редактор, не уступающий по своим возможностям популярным текстовым процессорам.
10. ИНТЕГРАЦИЯ С ДРУГИМИ ПРИЛОЖЕНИЯМИ
Опции командной строки и поддержка Drag&Drop для вызова из внешних приложений, сканирования, распознавания и сохранения результатов в автоматическом режиме.
Скачать программу OCR CuneiForm (.zip-файл, 33,3 Мб.) Обратите внимание на вес файла!!!
CuneiForm – бесплатная утилита, предназначенная для быстрого преобразования изображения в текстовый формат. Программа находит свое применение во многих сферах: в школах, в университетах, офисной работе, при оцифровке старых архивов, книг и прочих документов.
Чем же данный инструмент лучше Finereader для обычного пользователя? Прежде всего, бесплатностью. Стоимость вышеупомянутого софта составляет 5776 рублей, в то время, как за CuneiForm OpenOCR вы не платите ровным счетом ничего. Просто устанавливаем и пользуемся. Кстати, скачать CuneiForm вы сможете прямо на данной странице (внизу мы разместили ссылку на официальную версию программы). Сразу после установки открываем наш распознаватель и читаем небольшую инструкцию к нему:
Итак, как происходит преобразование картинки в текст? В данной программе будет очень просто работать и новичку, и профессионалу, ведь для распознавания нужно сделать всего пару действий. Во-первых, вам необходимо какое-то изображение (любого формата – PNG, BMP, JPEG и т.п.), поэтому открываем нужный объект.

Во-вторых, необходимо нажать на кнопку «Распознать». Далее, в CuneiForm запускается процесс распознавания текста. Это, как правило, происходит очень быстро, только в редких случаях нужно ждать больше 5-10 секунд.

После того, как инструмент распознал текст, открывается ваш стандартный текстовый редактор — Word, WordPad и т.п. Кстати, здесь же можно отредактировать полученный текст, ибо далеко не всегда утилита выдает точный результат, особенно при обработки испорченных, старых страниц.

Также далеко не всегда CuneiForm OpenOCR может выделить области текста, т.е. таблицы, абзацы, заголовки и прочие разделы. В такой ситуации вам необходимо вручную выполнить разметку страницы, для этого создан отдельный, удобный инструмент.

Для большего удобства разработчики добавили функцию сканирования. Ты просто кладешь в МФУ или сканер какой-то документ или книгу, сканируешь нужный участок, а после Кьюниформ автоматически преобразовывает текст в изображение — очень полезный инструмент.

Общих параметров здесь не так много, можно настроить всего 3 – разметка, сканирование и форматирование, но это компенсируется тем, что можно настраивать каждый модуль отдельно, так что пользователь все может настроить под себя. Кстати, сама утилита достаточно простая и совместима с любой ОС:

Чтобы скачать CuneiForm бесплатно на русском, посетите официальный сайт разработчиков, там вы получите полную информацию о программе. Если вы уже поняли, как с ней работать, то просто нажмите на зеленую кнопку, и тогда вы получите отличный распознаватель текста, скачав его с официального сайта без вирусов и СМС-подписок.
CuneiForm — это программа для оптического распознавания текста документов в редактируемый вид. Результаты работы программы можно редактировать в офисных программах и текстовых редакторах и сохранять в популярных форматах, проводить по ним полнотекстовый поиск. Однако для Linux имеется только консольная версия программы, поэтому гораздо удобнее пользоваться вместе с фронт-эндом YAGF.
Оболочка YAGF — Y et A nother G raphical F ront-end for CuneiForm предоставляет графический интерфейс для консольной программы распознавания текстов CuneiForm на платформе Linux. Кроме того, YAGF позволяет управлять сканированием изображений, их предварительной обработкой и собственно распознаванием из единого центра. Программа YAGF также упрощает последовательное распознавание большого числа сканированных страниц.
Программа CuneiForm имеется в стандартном репозитории Ubuntu, а вот для YAGF необходимо подключить один из дополнительных репозиториев:
Ppa:alex-p/notesalexp deb http://archive.getdeb.net/ubuntu natty-getdeb apps
и установить с помощью Центра приложений Ubuntu.
Для работы YAGF необходим пакет проверки орфографии aspell и словари соответствующих языков (aspell-en, aspell-ru и т.д.). Если вы хотите управлять сканированием изображений напрямую из YAGF, установите программу XSane. Для распознавания текста потребуется, естественно, программа CuneiForm.
Работа в YAGF состоит из нескольких этапов: получение изображения (серии изображений) страниц; подготовка к распознаванию (если необходимо); распознавание; сохранение результатов.
Вы можете использовать файлы изображений, сохраненные на жестком диске, или отсканировать новое изображение. Для того чтобы загрузить изображение, воспользуйтесь командой Файл/Открыть (вы можете открыть несколько файлов сразу). Вы также можете перетащить графически файлы мышью на темную полосу в левой части главного окна программы, в результате чего они будут загружены в программу. YAGF поддерживает все основные растровые графические форматы (JPEG , PNG , BMP, TIFF , GIF , PNM, PPM, PBM и другие). Если имя открытого файла имеет вид nameXXX.ext, где XXX - последовательность цифр, вы можете переходить к предыдущему/следующему файлам с помощью кнопок перехода, расположенных на панели быстрого доступа. Например, если вы открыли файл MyPage001.jpg, то при щелчке кнопки перехода к следующему изображению программа попытается открыть файл MyPage002.jpg.
Вы можете получать изображения напрямую со сканера с помощью программы XSane. Находясь в YAGF, скомандуйте Файл/Сканировать. Будет запущена программа XSane. Настройте параметры сканирования в XSane и нажмите кнопку «Сканировать». По окончании сканирования в окне просмотра изображений YAGF появится отсканированное изображение. Если вам нужно отсканировать несколько изображений, выполняйте эти операции несколько раз (в окне просмотра изображений всегда будет открыто последнее отсканированное изображение, вы можете перейти к предыдущим изображениям, используя команды перемещения). Вы можете работать в YAGF, не закрывая окно XSane. Если вам нужно отсканировать очередное изображение, просто щелкните кнопку XSane «Сканировать». При выходе из YAGF открытое программой окно XSane будет закрыто автоматически. Для перехода к другим отсканированным изображениям пользуйтесь кнопками с панели быстрого доступа, как было описано выше. Все полученные изображения отображаются в уменьшенном виде на панели изображений в левой части главного окна программы. Вы можете сохранить эти изображения в отдельную директорию с помощью кнопки «Сохранить».
В YAGF вы можете выполнять простые операции подготовки отсканированного изображения: выделение блока текста для распознавания и поворот. Если изображение ориентировано неправильно, его можно повернуть на 90 градусов по и против часовой стрелки или на 180 градусов. Делается это с помощью кнопок панели быстрого доступа в окне просмотра изображений. Если вы хотите передать на распознавание не все отсканированное изображение, а его часть, вы можете выделить мышью один или несколько прямоугольных блоков в окне просмотра изображений. Если щелкнуть левой кнопкой мыши по существующему блоку, его цвет изменится на розовый. Теперь размер выбранного блока можно изменить, «ухватившись» мышью за край блока. Если щелкнуть в окне изображения правой кнопкой мыши, появится контекстное меню, с помощью которого можно удалить все выделенные блоки, удалить выбранный блок, распознать текст выбранного блока. Для удобства выделения блоков вы можете уменьшить или увеличить размеры изображения в окне просмотра (эта операция не влияет на размеры изображения, передаваемого программе CuneiForm). Изменение видимых размеров изображения можно выполнить так же с помощью комбинаций клавиш Ctrl++ и Ctrl+- или вращая колесико мыши, удерживая при этом клавишу Ctrl (точно так же можно изменить размеры шрифта в окне просмотра текста).
Если в программе открыто несколько страниц и для каждой выбраны своя ориентация, свой масштаб и выделены свои блоки, YAGF запомнит эти параметры для каждой страницы.
Если страница отсканирована неровно, с наклоном, вы можете попробовать исправить наклон с помощью новой функции «Исправить наклон страницы». Для этого нажмите соответсвующую кнопку.
Приступая к распознаванию, вы должны выбрать подходящий язык распознавания (или пару языков, если распознаваемый документ написан на нескольких языках). Основная версия CuneiForm позволяет вам распознавать тексты почти на всех европейских языках, а также тексты, содержащие пару языков русский-английский.
Каждый новый распознанный фрагмент текста (выделенный блок или новая страница) добавляется в редактор распознанного текста в виде нового абзаца.
По умолчанию YAGF выполняет проверку орфографии распознанного текста с помощью libaspell. Обычно в вашей системе устанавливаются орфографические словари для «родной» локали система и английского. Если вы хотите проверять орфографию для текстов на других языках, установите соответствующие словари. Если YAGF не находит нужного словаря для проверки орфографии для заданного языка распознавания, программа предупреждает вас об этом. Отключите проверку орфографии, если не хотите получать такие предупреждения.
Если вам нужно распознать текст сразу с нескольких изображений, вы можете воспользоваться пакетным распознаванием. Для этого все изображения, которые требуется распознать, должны быть открыты на панели изображений (в левой части окна программы). Щелкните кнопку «Распознать все страницы». Все открытые изображения будут загружаться и распознаваться автоматически. При этом будет выведено диалоговое окно, отображающее прогресс распознавания. Вы можете остановить процесс пакетного распознавания, щелкнув кнопку «Прервать». Если на распознаваемых страницах выделены блоки, будет распознан только текст внутри блоков.
Распознанный текст может быть сохранен на диске в текстовом формате (кодировка UTF-8), в формате HTML или скопирован в буфер обмена. Кнопка «Копировать текст в буфер обмена» копирует в буфер выделенный фрагмент распознанного текста или весь текст, если в редакторе отсутствует выделение.

Все знают, что существует возможность переустановки операционной системы или же ее замена другим дистрибутивом. Но многие...
Последняя версия ОС Windows 10 имеет свои специфические отличия. В нее изначально встроено несколько полезных программ,...
Если вы хотите, чтобы ваш блог, ваш сайт или ваш бутик ан Ligne работает нормально, было бы идеально рассмотреть вопрос...

2 года назад 0 Больше месяца пользуясь. Шустро работает. Быстро откликается 2 года назад 0...
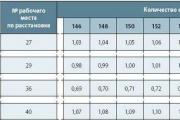
Система премирования Тарифная система надбавок и доплат может дополняться премиальной системой. Под премированием...

Не часто встретишь людей которым нравится система 1С-Битрикс и их подход к разработке. Но почему-то же его используют?...

Большинство игр от компании Bethesda разработаны на одном движке и работают по одному и тому же принципу. Из-за...
CSV (Comma-Separated Values) представляет собой файл текстового формата, который предназначен для отображения...
Требуется зафиксировать результат, чтобы исключить возможность редактирования. Один из вариантов, как добиться...

Принтер - в числе самых нужных современному пользователю устройств. Выпускаются данные девайсы в широком...

Статьи и ЛайфхакиПонять, как настроить почту на андроиде , совершенно не сложно. Следуя изложенной в данной...

Следуйте инструкциям ниже, чтобы дать гостевой, полный или предоставить публичный доступ к статистике Вашего...

Рано или поздно у всех владельцев планшетов на Андроид возникает мысль об обновлении прошивки на более свежую...

Стандартные методы переключения Windows между активными аудиоустройствами неудобны. От версии к версии комфорта...
Последняя версия ОС Windows 10 имеет свои специфические отличия. В нее изначально встроено несколько полезных...
Если вы хотите, чтобы ваш блог, ваш сайт или ваш бутик ан Ligne работает нормально, было бы идеально...